Vous venez découper un fichier en colonnes pour en extraire les morceaux qui vous intéressent, sans doute avec awk parce qu'on vous a dit que c'était l'outil pour ça. On avait raison. Les recettes que vous tapez vraiment sont juste en dessous, les plus demandées en premier, pour que vous puissiez copier, changer le numéro de champ, et retourner au fichier devant vous. Un truc à savoir avant de scroller : awk lit un fichier ligne par ligne, découpe chaque ligne en champs sur les espaces par défaut, et les numérote $1, $2, et ainsi de suite, $0 étant la ligne entière et $NF le dernier champ. Presque tout le reste se construit là-dessus.
The short answer
Les recettes que vous tapez vraiment, vite : awk '{print $1}' pour la première colonne
et $NF pour la dernière, awk -F, '{print $2}' pour découper un CSV, awk '/error/' fichier pour filtrer les lignes comme grep, awk '$3 > 100' pour garder des lignes par
valeur, et awk '{sum += $1} END {print sum}' pour totaliser une colonne. BEGIN passe
en premier, END en dernier.

{kind=link}
Vous venez découper un fichier en colonnes pour en extraire les morceaux qui vous intéressent, sans doute avec awk parce qu'on vous a dit que c'était l'outil pour ça. On avait raison. Les recettes que vous tapez vraiment sont juste en dessous, les plus demandées en premier, pour que vous puissiez copier, changer le numéro de champ, et retourner au fichier devant vous.
Un truc à savoir avant de scroller. awk lit un fichier ligne par ligne, découpe chaque ligne en champs sur les espaces par défaut, et les numérote $1, $2, et ainsi de suite. $0 est la ligne entière, et $NF est le dernier champ peu importe combien il y en a. Presque tout ce qui suit se construit sur cette seule idée, donc une fois que ça fait tilt, le reste n'est que des variations.
Afficher une colonne : $1, $3, $NF
Celle que tout le monde veut en premier. Mettez le programme entre apostrophes simples pour que le shell laisse les $ tranquilles, et nommez le champ voulu. $1 est la première colonne, $NF la dernière, et $0 la ligne entière.
| Recette | Ce qu'elle fait |
|---|---|
awk '{print $1}' fichier | La première colonne de chaque ligne |
awk '{print $3}' fichier | La troisième colonne |
awk '{print $NF}' fichier | La dernière colonne, quelle que soit sa position |
awk '{print $(NF-1)}' fichier | L'avant-dernière colonne |
awk '{print $1, $3}' fichier | Les colonnes 1 et 3, jointes par une espace |
La virgule dans print $1, $3 compte. Avec une virgule vous obtenez les deux valeurs séparées par une espace (le séparateur de sortie, OFS). Enlevez la virgule et écrivez print $1 $3 et awk les colle l'une à l'autre sans rien entre, ce qui n'est presque jamais ce que vous vouliez.
Régler le séparateur de champ : -F
Par défaut awk découpe sur les suites d'espaces, donc un CSV ou /etc/passwd le perturbe. La solution est -F, placé avant le programme, qui dit à awk sur quoi découper.
| Recette | Ce qu'elle fait |
|---|---|
awk -F, '{print $2}' fichier.csv | Découpe sur les virgules, affiche le deuxième champ |
awk -F: '{print $1}' /etc/passwd | Découpe sur les deux-points, affiche les noms d'utilisateur |
awk -F'\t' '{print $1}' fichier.tsv | Découpe sur les tabulations |
awk -F'[,;]' '{print $1}' fichier | Découpe sur une virgule ou un point-virgule (regex) |
Le séparateur peut être un seul caractère, plusieurs caractères, ou une expression régulière. Si vous voulez aussi que vos colonnes de sortie soient jointes par quelque chose de précis, réglez OFS dans un bloc BEGIN, comme dans awk 'BEGIN {FS=","; OFS="\t"} {print $1, $2}', qui lit un CSV et écrit un TSV.
Filtrer les lignes par motif
C'est là qu'awk commence à ressembler à grep avec une cervelle. Un motif devant l'action décide sur quelles lignes l'action tourne. Omettez l'action et une ligne qui correspond est affichée en entier.
| Recette | Ce qu'elle fait |
|---|---|
awk '/error/' fichier | Affiche les lignes contenant error, comme grep |
awk '!/debug/' fichier | Affiche les lignes ne contenant pas debug |
awk '$3 > 100' fichier | Les lignes où le troisième champ dépasse 100 |
awk '$1 == "GET"' access.log | Les lignes où le premier champ vaut GET |
awk 'NR > 1' fichier | Saute l'en-tête, affiche à partir de la ligne 2 |
awk 'NF == 0' fichier | Trouve les lignes vides (zéro champ) |
La séparation entre motif et action est tout le modèle : motif { action }. Chaque partie est facultative. Un motif seul veut dire « affiche la ligne », et une action seule sans motif veut dire « tourne sur chaque ligne ». Donc awk '$3 > 100 {print $1}' se lit « sur les lignes où le champ trois dépasse 100, affiche le champ un ».
Calculer des sommes et des moyennes
Les nombres, c'est là qu'awk justifie sa place face à un tube de cut et paste. Les variables partent de zéro, persistent sur chaque ligne, et vous les affichez à la fin. NR est le compteur courant d'enregistrements (lignes) qu'awk a lus.
| Recette | Ce qu'elle fait |
|---|---|
awk '{sum += $1} END {print sum}' fichier | Totalise la première colonne |
awk '{sum += $1} END {print sum / NR}' fichier | La moyenne de la première colonne |
awk 'END {print NR}' fichier | Compte les lignes (comme wc -l) |
awk '$1 > max {max = $1} END {print max}' fichier | La plus grande valeur de la colonne 1 |
awk '{sum += $3} $3 > 0 {n++} END {print sum/n}' fichier | Moyenne en ignorant les zéros |
Si vous voulez un total par groupe plutôt qu'un seul grand total, utilisez un tableau indexé par une colonne. Ceci somme les octets du champ 7 d'un journal d'accès, groupés par le code de statut du champ 9, et affiche chaque groupe une fois à la fin :
awk '{bytes[$9] += $7} END {for (code in bytes) print code, bytes[code]}' access.logLes tableaux awk sont associatifs, donc la clé peut être n'importe quelle chaîne. Ce seul motif, accumuler dans tableau[clé] puis boucler dessus dans END, couvre une part étonnante des rapports réels.
Les blocs BEGIN et END
Un programme awk complet a trois parties, et vous pouvez en utiliser n'importe quel sous-ensemble. BEGIN tourne une fois avant la première ligne, les règles du milieu tournent sur chaque ligne, et END tourne une fois après la dernière. Utilisez BEGIN pour les en-têtes et la préparation, END pour les totaux et les résumés.
| Recette | Ce qu'elle fait |
|---|---|
awk 'BEGIN {print "debut"} {print} END {print "fini"}' | En-tête, corps, pied |
awk 'BEGIN {FS=":"} {print $1}' /etc/passwd | Régle le séparateur dans BEGIN |
awk 'END {print NR " lignes"}' fichier | Un résumé d'une ligne à la fin |
awk 'BEGIN {OFS="\t"} {print $1, $2}' fichier | Régle le séparateur de sortie d'abord |
Voici la forme d'un petit rapport qui utilise les trois, affichant un en-tête, les lignes qui l'intéressent, et un total. Enregistrez-le ou collez-le directement :
awk 'BEGIN { print "user bytes" }
$9 == 200 { print $1, $7; total += $7 }
END { print "total", total }' access.logLes champs s'alignent parce qu'awk se moque de vos espaces à l'intérieur du programme. Vous pouvez étaler une règle sur plusieurs lignes pour la lisibilité, ce qui vaut mieux que tasser un vrai rapport sur une seule ligne et plisser les yeux dessus plus tard.
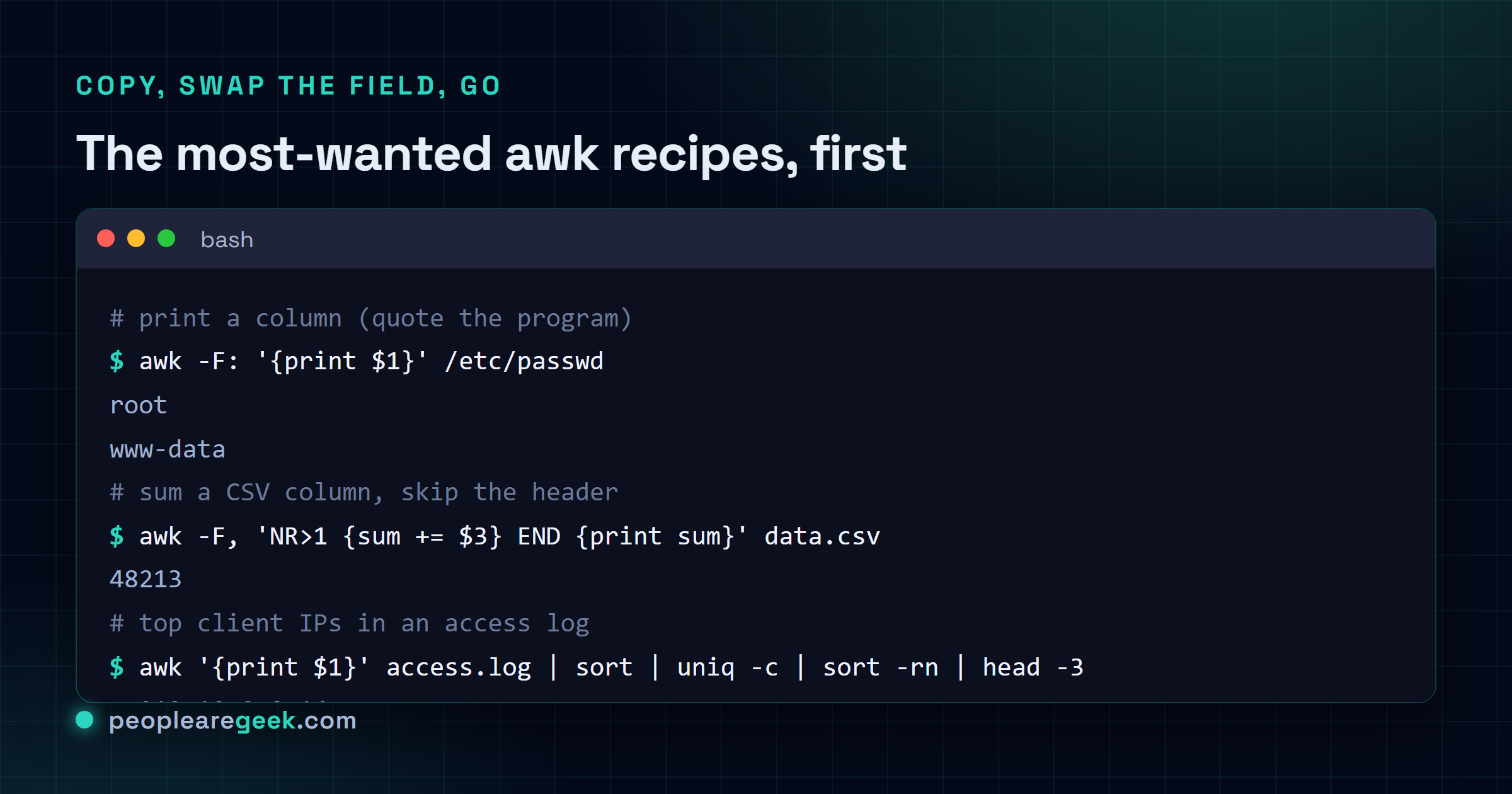
awk -F: '{print $1}' /etc/passwd | sort Cette dernière, c'est le genre qu'on tape sans réfléchir une fois le modèle ancré : découper /etc/passwd sur les deux-points, afficher les noms d'utilisateur du champ un, et les passer à sort. Pas de fichier temporaire, pas d'éditeur, juste la colonne que vous vouliez.
One-liners pour les logs et le CSV
La trousse de travail, les lignes qui paient vraiment le loyer. Elles supposent un journal d'accès Apache ou Nginx au format courant (IP en premier, statut au champ 9, octets au champ 10) et un CSV séparé par des virgules. Changez les numéros de champ pour coller à votre propre disposition.
| Recette | Ce qu'elle fait |
|---|---|
awk '{print $1}' access.log | sort | uniq -c | sort -rn | Top des IP clientes par nombre de hits |
awk '$9 == 404 {print $7}' access.log | Chaque URL en 404 |
awk '$9 >= 500' access.log | Toutes les erreurs serveur (5xx) |
awk -F, 'NR > 1 {sum += $3} END {print sum}' data.csv | Somme une colonne CSV, en sautant l'en-tête |
| `awk -F, 'NR == 1 | |
awk -F, '{print NF; exit}' data.csv | Combien de colonnes ce CSV a-t-il |
awk -F, '!seen[$1]++' data.csv | Enlève les doublons par le premier champ |
Cette astuce !seen[$1]++ mérite un deuxième regard, parce qu'elle apparaît partout. Elle utilise le champ un comme clé d'un tableau. La première fois qu'une valeur apparaît, seen[$1] vaut zéro, !0 est vrai, donc la ligne s'affiche, puis ++ pousse le compteur à un. Chaque copie suivante trouve un compteur non nul, !1 est faux, et la ligne est sautée. Le résultat est un dédoublonnage stable qui garde la première occurrence et l'ordre d'origine, ce que sort -u ne peut pas vous donner.

{kind=link}
Et après
Voilà la trousse de travail. Afficher une colonne, régler le séparateur, filtrer les lignes, totaliser une colonne, et l'échafaudage BEGIN/END qui transforme tout ça en vrai rapport. La plupart de l'awk quotidien est un mélange de ça, et les fonctionnalités profondes du langage (fonctions, tableaux multidimensionnels, getline) attendent tranquillement le jour rare où vous en avez besoin.
Si votre manipulation de texte va au-delà des colonnes, le même réflexe se transpose. Vous cherchez des fichiers par nom, taille ou âge ? Voyez l'antisèche de la commande find, qui se marie bien avec awk quand vous lui passez une liste de chemins. Vous dégainez chercher-remplacer sur un flux plutôt que par champ ? Une bonne référence sed couvre les substitutions où awk est maladroit. Des outils différents, la même habitude : arrêtez de mémoriser, gardez une antisèche solide à portée.
Questions fréquentes
Comment afficher une colonne precise avec awk ?
Utilisez awk avec le numero de champ voulu : awk '{print $1}' fichier affiche la premiere colonne, awk '{print $3}' la troisieme, et awk '{print $NF}' la derniere quelle que soit sa position. Les champs sont decoupes sur les suites d'espaces par defaut et numerotes a partir de 1, tandis que $0 est la ligne entiere. Pour afficher deux colonnes separees par une espace, listez-les avec une virgule : awk '{print $1, $3}'.
Comment changer le separateur de champ dans awk ?
Passez -F suivi du separateur, avant le programme. Pour un CSV vous ecririez awk -F, '{print $2}' fichier, et pour le /etc/passwd separe par des deux-points vous ecririez awk -F: '{print $1}' /etc/passwd. Le separateur peut faire plus d'un caractere ou etre une regex, donc -F"\t" decoupe sur les tabulations et -F"[,;]" decoupe sur une virgule ou un point-virgule. Reglez OFS de la meme facon si vous voulez aussi controler comment les champs de sortie sont joints.
Comment sommer une colonne de nombres avec awk ?
Ajoutez le champ a un total courant a chaque ligne, puis affichez-le a la fin : awk '{sum += $1} END {print sum}' fichier. Les variables awk partent de zero et persistent d'une ligne a l'autre, donc sum grossit a mesure que chaque ligne est lue, et le bloc END s'execute une fois apres la derniere ligne. Pour une moyenne, comptez aussi les lignes et divisez : awk '{sum += $1} END {print sum / NR}' fichier, ou NR est le nombre d'enregistrements vus par awk.
A quoi servent les blocs BEGIN et END dans awk ?
BEGIN s'execute une fois avant la lecture de toute ligne, et END une fois apres la derniere. On utilise BEGIN pour afficher un en-tete ou regler une variable comme le separateur, et END pour afficher un total ou un resume construit pendant la lecture. Un programme peut avoir les trois parties : un bloc BEGIN, une ou plusieurs regles motif et action pour les lignes entre les deux, et un bloc END. Chaque bloc special est facultatif, et beaucoup de one-liners n'utilisent que END.
Comment filtrer les lignes par motif dans awk ?
Mettez la condition devant l'action, ou utilisez-la seule. awk '/error/' fichier affiche chaque ligne contenant error, comme le ferait grep, tandis que awk '$3 > 100' fichier affiche les lignes dont le troisieme champ depasse 100. Combinez un test et une action comme awk '$1 == "GET" {print $7}' pour afficher le septieme champ seulement sur les lignes ou le premier vaut GET. Sans action, une ligne qui correspond est affichee en entier.