Le meilleur modèle IA pour coder en 2026 n'est pas un seul nom, c'est une liste courte classée par un chiffre honnête : SWE-bench Pro, le benchmark bâti à partir de vraies pull requests de dépôt plutôt que de puzzles jouets. Sur cette échelle, et parmi les modèles réellement achetables, Claude Opus 4.8 mène à 69,2, Claude Sonnet 5 est le choix valeur juste derrière, et les meilleurs modèles à poids ouverts se rapprochent vite. Deux astérisques à poser d'emblée : Claude Fable 5 détient le record absolu mais est suspendu, et GPT-5.6 domine certains tests mais reste une préversion limitée, donc aucun n'est un choix pratique aujourd'hui. Voici le classement, ce que chacun fait de mieux, et comment choisir, avec un lien vers l'analyse détaillée de chaque pick.
The short answer
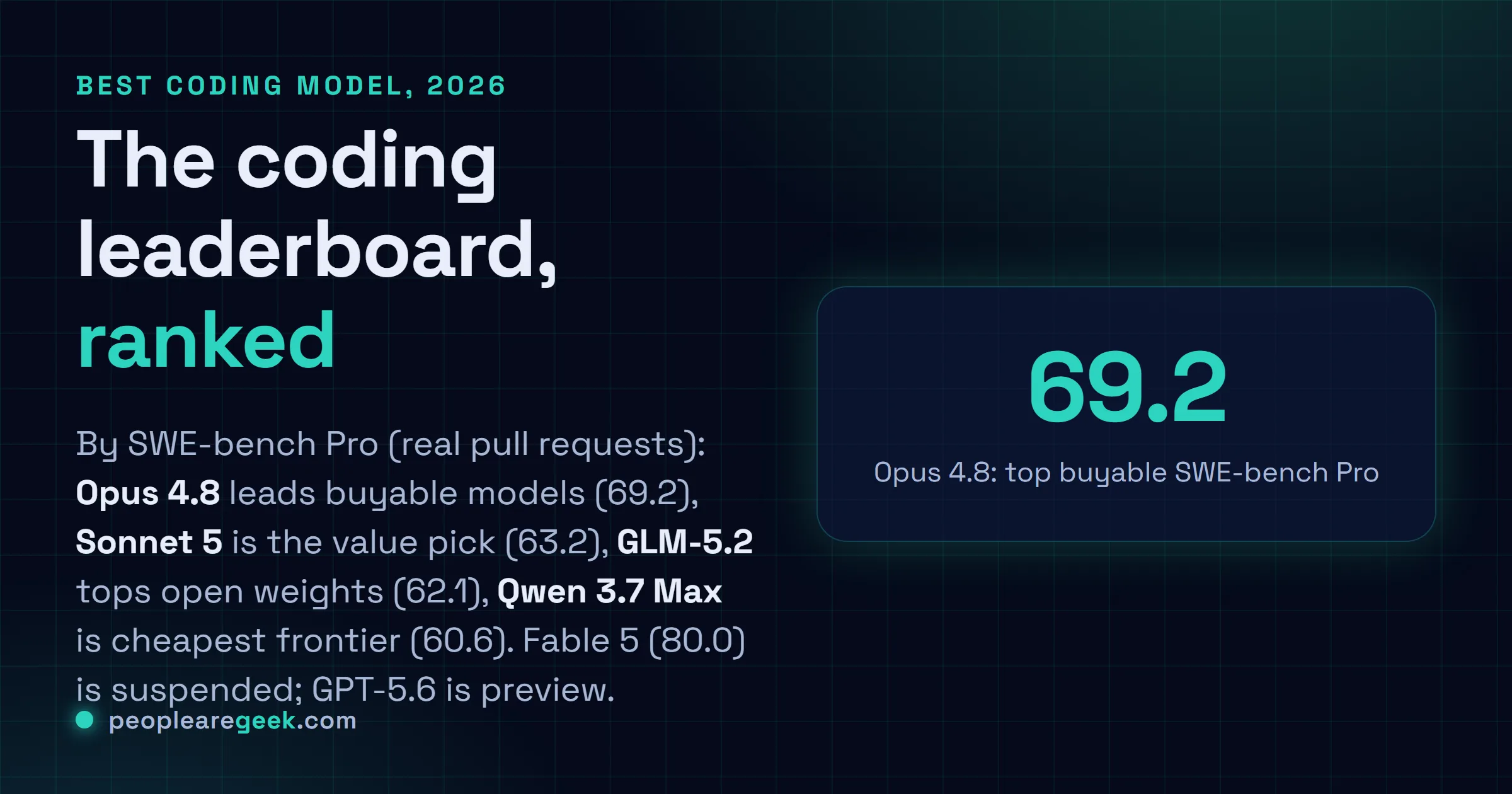
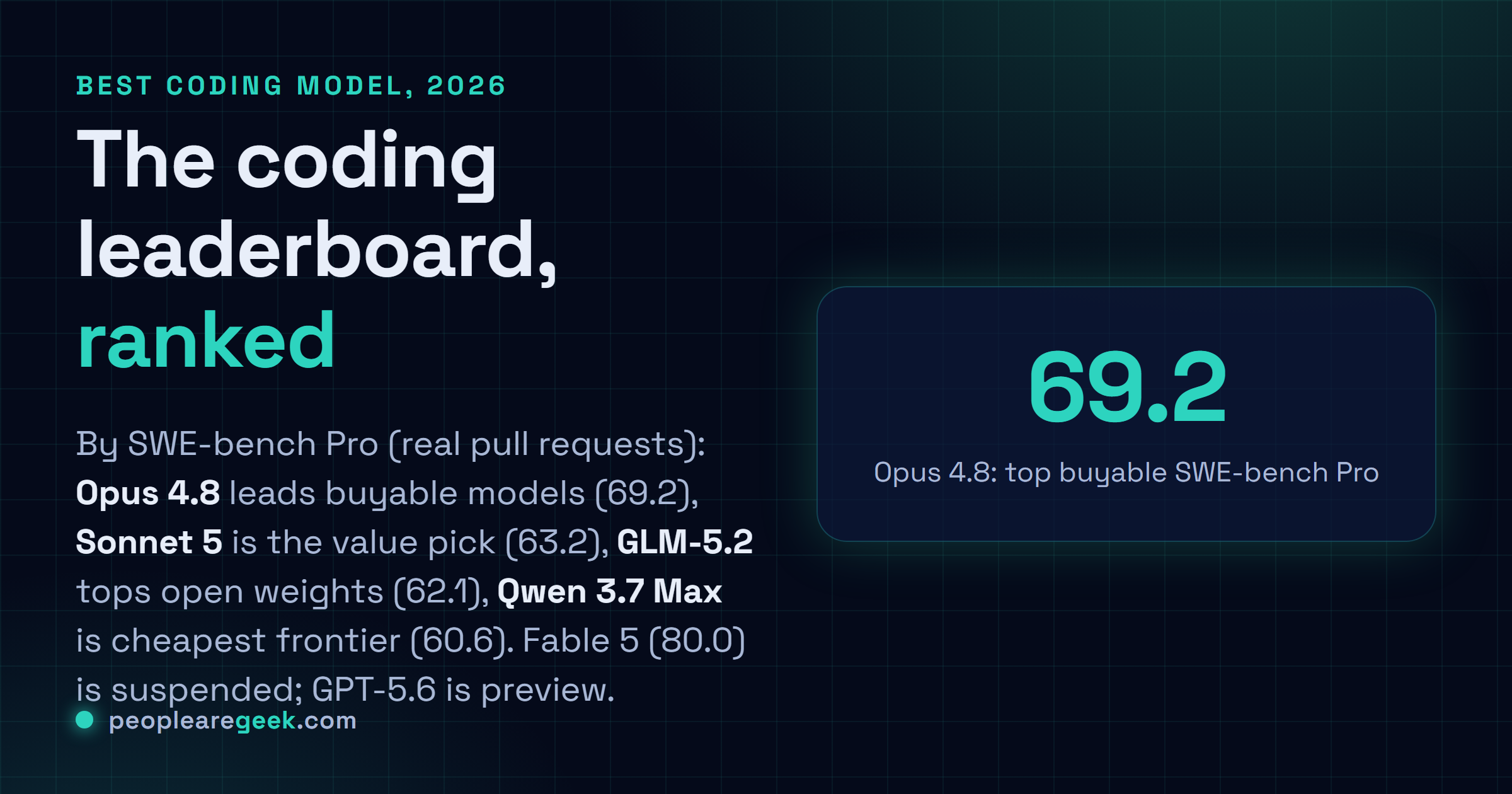
Classé par SWE-bench Pro, le benchmark des vraies pull requests : Claude Opus 4.8 (69,2) mène les modèles achetables, Claude Sonnet 5 (63,2) est le choix valeur juste derrière, GLM-5.2 (62,1) domine l'open, et Qwen 3.7 Max (60,6) est l'API frontière la moins chère. Claude Fable 5 (80,0) détient le record mais est suspendu ; GPT-5.6 mène certains tests mais reste une préversion.
{kind=link}
Chaque mois amène un nouveau titre « meilleur modèle de code », alors ancrons ceci à du concret : SWE-bench Pro, le benchmark bâti à partir de vraies pull requests de dépôt, qui corrèle bien mieux avec le code du quotidien que les tests façon puzzle. On classe par lui, on note le prix, et on ne met dans le tableau principal que les modèles réellement utilisables. Deux des meilleurs scores mondiaux ne passent pas cette dernière règle, on y viendra. D'abord, le classement.
Le classement
Classé par SWE-bench Pro, modèles achetables et exploitables aujourd'hui.
| # | Modèle | SWE-bench Pro | Prix, par 1M | Idéal pour |
|---|---|---|---|---|
| 1 | Claude Opus 4.8 | 69,2 | $5 / $25 | Le code le plus profond et le raisonnement le plus dur |
| 2 | Claude Sonnet 5 | 63,2 | $3 / $15 (intro $2/$10) | Le meilleur rapport global |
| 3 | GLM-5.2 (open) | 62,1 | poids ouverts | Le meilleur modèle auto-hébergeable |
| 4 | Qwen 3.7 Max | 60,6 | $2,50 / $7,50 | L'API de classe frontière la moins chère |
| 5 | MiniMax M3 (open) | 59,0 | poids ouverts | Alternative open à GLM |
| 6 | GPT-5.5 | 58,6 | $5 / $30 | Le sortant OpenAI |
Deux astérisques planent au-dessus de ce tableau. Claude Fable 5 a marqué 80,0, le record absolu, mais il est suspendu et indisponible. GPT-5.6 mène des tests comme Terminal-Bench dans sa préversion, et son palier Sol défiera probablement le sommet, mais c'est une préversion limitée à environ 20 organisations, pas quelque chose que la plupart des équipes peuvent déployer.
Le meilleur achetable : Claude Opus 4.8
À 69,2 sur SWE-bench Pro et 88,6 sur le SWE-bench Verified plus facile, Opus 4.8 est le modèle de code le plus fort qu'on puisse vraiment payer par carte. C'est le modèle le plus autonome d'Anthropic pour l'agentique au long cours, et c'est de là que viennent les derniers points de justesse sur les changements vraiment durs et multi-étapes. Le coût est le prix fleuron, 5 dollars en entrée et 25 en sortie le million. Savoir s'il les vaut face à Sonnet 5 dépend entièrement de votre charge, la question exacte à laquelle on répond dans Claude Sonnet 5 vs Opus 4.8.
Le meilleur rapport : Claude Sonnet 5
Sonnet 5 est l'histoire des modèles de code de 2026. À 63,2 il se place juste derrière Opus, il bat même Opus sur les tâches d'agent en terminal, et coûte 40 pour cent de moins au tarif standard (60 pour cent en intro). Pour la grande majorité du code, c'est le défaut raisonnable, et il est disponible aujourd'hui, y compris dans Claude Code. Si vous le pesez aussi face à OpenAI, voyez Claude Sonnet 5 vs GPT-5.6.
Le meilleur open : GLM-5.2 et la voie locale
Si vous voulez un modèle à télécharger et faire tourner soi-même, GLM-5.2 mène l'open à 62,1, avec MiniMax M3 juste derrière à 59,0. Les deux se placent à quelques points des meilleurs modèles fermés, ce qui n'était pas vrai il y a un an. Pour la confidentialité, l'usage hors ligne, ou la génération illimitée sans compteur au token, l'open est désormais un vrai choix, pas un compromis. Pour en installer un sur votre matériel, notre guide sur faire tourner Qwen en local couvre la voie Ollama, les paliers matériels et la quantification, et les mêmes étapes valent pour GLM et MiniMax.
L'API frontière la moins chère : Qwen 3.7 Max
Parmi les modèles fermés de classe frontière, Qwen 3.7 Max est le leader valeur à 60,6, et il passe sous tout le monde sur le prix à environ 2,50 en entrée et 7,50 en sortie le million, à peu près un tiers du coût de sortie de GPT-5.5. Il gagne vraiment le code réel pour l'argent, d'où son analyse dédiée face à OpenAI dans Qwen 3.7 Max vs GPT-5.5. Au coût brut par tâche résolue, Claude Haiku 4.5 est encore moins cher, à environ 13 cents de sortie par point, idéal pour le code simple à gros volume.
Les astérisques : suspendu et préversion
Deux modèles marquent plus haut que tout le tableau mais ne comptent pas comme choix pratiques. Claude Fable 5 détient le record à 80,0, mais lui et Mythos 5 ont été suspendus, donc vous ne pouvez pas les utiliser, une histoire qu'on a couverte dans la suspension de Fable 5 et Mythos 5. GPT-5.6 mène plusieurs tests en préversion, et ses paliers valent d'être compris avant l'ouverture, ce qu'on décortique dans GPT-5.6 Sol vs Terra vs Luna. Les deux signalent que le plafond est plus haut que ne le montre le classement en vente actuel.
Comment choisir, et essayer
Ramenons à la décision. Pour la plupart des équipes : par défaut Sonnet 5, escalade des tâches les plus dures vers Opus 4.8, et recours aux poids ouverts (GLM-5.2 ou un Qwen local) quand la confidentialité ou le coût l'exigent. Qwen 3.7 Max est l'API frontière la moins chère, et Haiku 4.5 le champion du coût par tâche pour le travail simple. La bonne nouvelle, c'est qu'essayer les meilleurs prend quelques minutes.

{kind=link}
Le mot de la fin
Le meilleur modèle IA pour coder en 2026, parmi les achetables, est Claude Opus 4.8, mais la réponse la plus utile est que Claude Sonnet 5 a fait de « prends juste le fleuron » le mauvais défaut pour la plupart des équipes, que l'open est devenu assez bon pour compter, et que la vraie frontière (Fable 5, GPT-5.6) reste juste hors de portée. Adaptez le modèle à la tâche, gardez un oeil sur le palier préversion, et re-vérifiez le classement souvent, car à ce rythme il rebougera le mois prochain.
Sources et pour aller plus loin
- Classement SWE-bench Pro (morphllm)
- Meilleur modèle IA pour coder, classé par SWE-bench Pro et coût (morphllm)
- Benchmarks Claude, tous les modèles et prix (morphllm)
- Classement SWE-bench Pro 2026 (CodingFleet)
Questions fréquentes
Quel est le meilleur modèle IA pour coder en 2026 ?
Parmi les modèles réellement achetables, Claude Opus 4.8 mène, avec 69,2 sur SWE-bench Pro (le benchmark des vraies pull requests) et 88,6 sur le SWE-bench Verified plus facile. Mais Claude Sonnet 5 à 63,2 est le choix valeur, proche du sommet pour 40 à 60 pour cent moins cher. Claude Fable 5 détient le record absolu à 80,0 mais est suspendu et indisponible, et GPT-5.6 reste une préversion limitée, donc aucun ne compte encore comme choix pratique. Pour la plupart des équipes, la réponse honnête est Sonnet 5 par défaut, Opus 4.8 pour le plus dur.
Quel est le meilleur modèle open source pour coder ?
GLM-5.2 mène le terrain des poids ouverts sur SWE-bench Pro à 62,1, devant MiniMax M3 à 59,0. Les deux sont à quelques points des meilleurs modèles fermés, ce qui est remarquable pour des poids qu'on télécharge et fait tourner soi-même. Si votre raison de passer à l'open est la confidentialité ou l'auto-hébergement, c'est désormais une vraie option. Pour faire tourner un modèle ouvert sur votre propre matériel, notre guide sur faire tourner Qwen en local détaille la mise en place avec Ollama.
Quel est le modèle de code correct le moins cher ?
Au coût par tâche résolue, Claude Haiku 4.5 est le moins cher, à environ 13 cents de sortie par point de benchmark, résolvant une bonne part des tâches à une fraction du prix fleuron. Parmi les modèles d'API de classe frontière, Qwen 3.7 Max est le moins cher à environ 2,50 dollars en entrée et 7,50 en sortie le million, à peu près un tiers du prix de sortie de GPT-5.5. Le tarif d'introduction de Claude Sonnet 5 à 2 et 10 le rend aussi très rentable pour son score.
Pourquoi GPT-5.6 n'est-il pas en tête du classement ?
Parce que la plupart des gens ne peuvent pas encore l'utiliser. GPT-5.6, et son palier fleuron Sol, est une préversion limitée pour environ 20 organisations partenaires, pas dans ChatGPT, avec une disponibilité générale promise dans les semaines à venir. Sur certains tests, comme Terminal-Bench, il mène le terrain, il défiera donc probablement le sommet une fois ouvert. Nous classons les modèles que les équipes peuvent réellement déployer aujourd'hui, d'où sa place en mention honorable plutôt que dans le tableau principal.
Claude Fable 5 est-il vraiment le numéro un du code ?
Sur le classement absolu SWE-bench Pro, oui, à 80,0, loin devant le reste. Le hic, c'est que Claude Fable 5, comme Mythos 5, a été suspendu, donc vous ne pouvez pas l'utiliser. C'est pourquoi notre classement des choix pratiques est mené par Claude Opus 4.8 à 69,2, le meilleur score parmi les modèles réellement achetables et exploitables. Fable 5 est le rappel que la frontière est plus haute que ce qui est actuellement en vente.