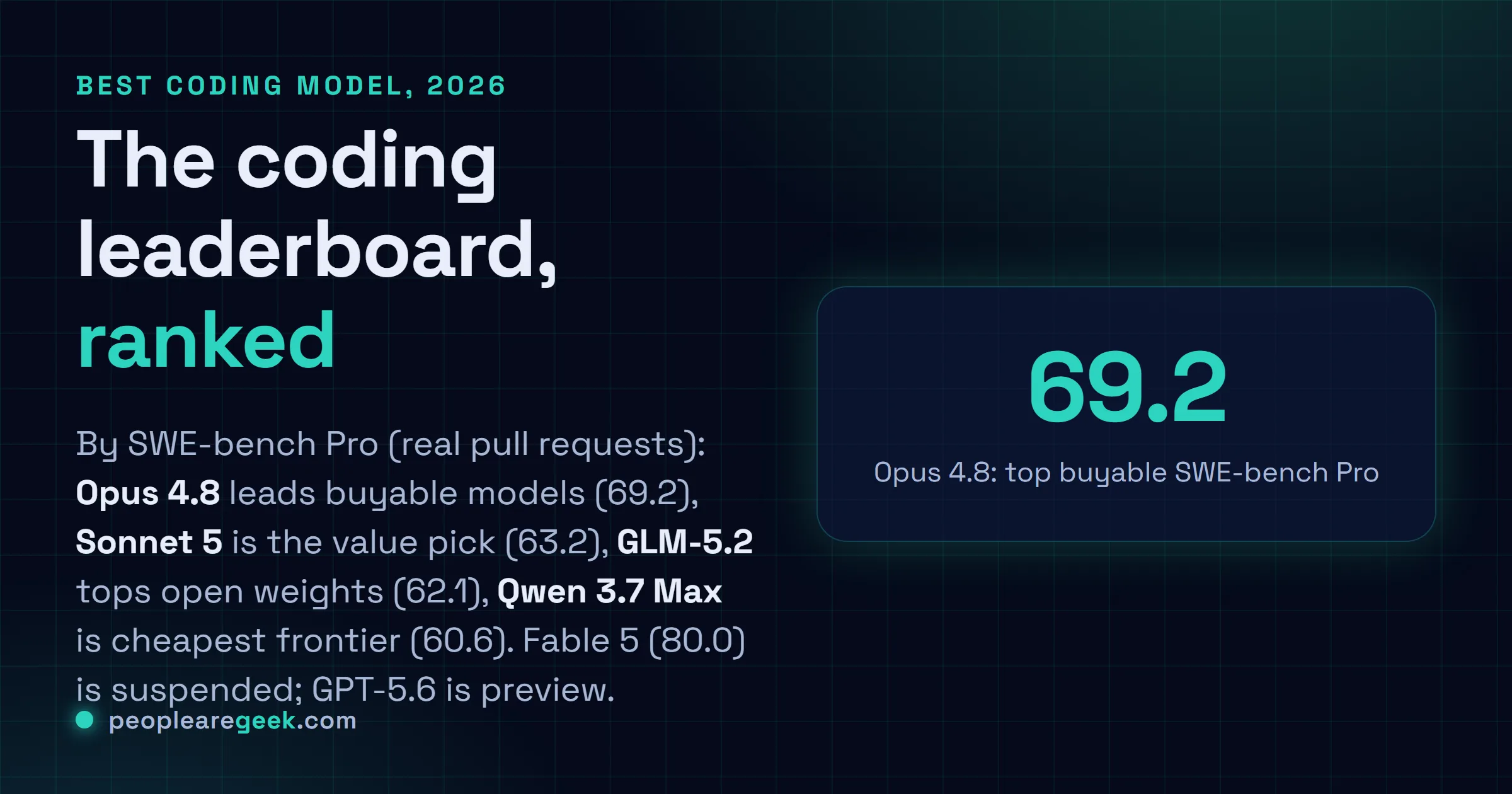
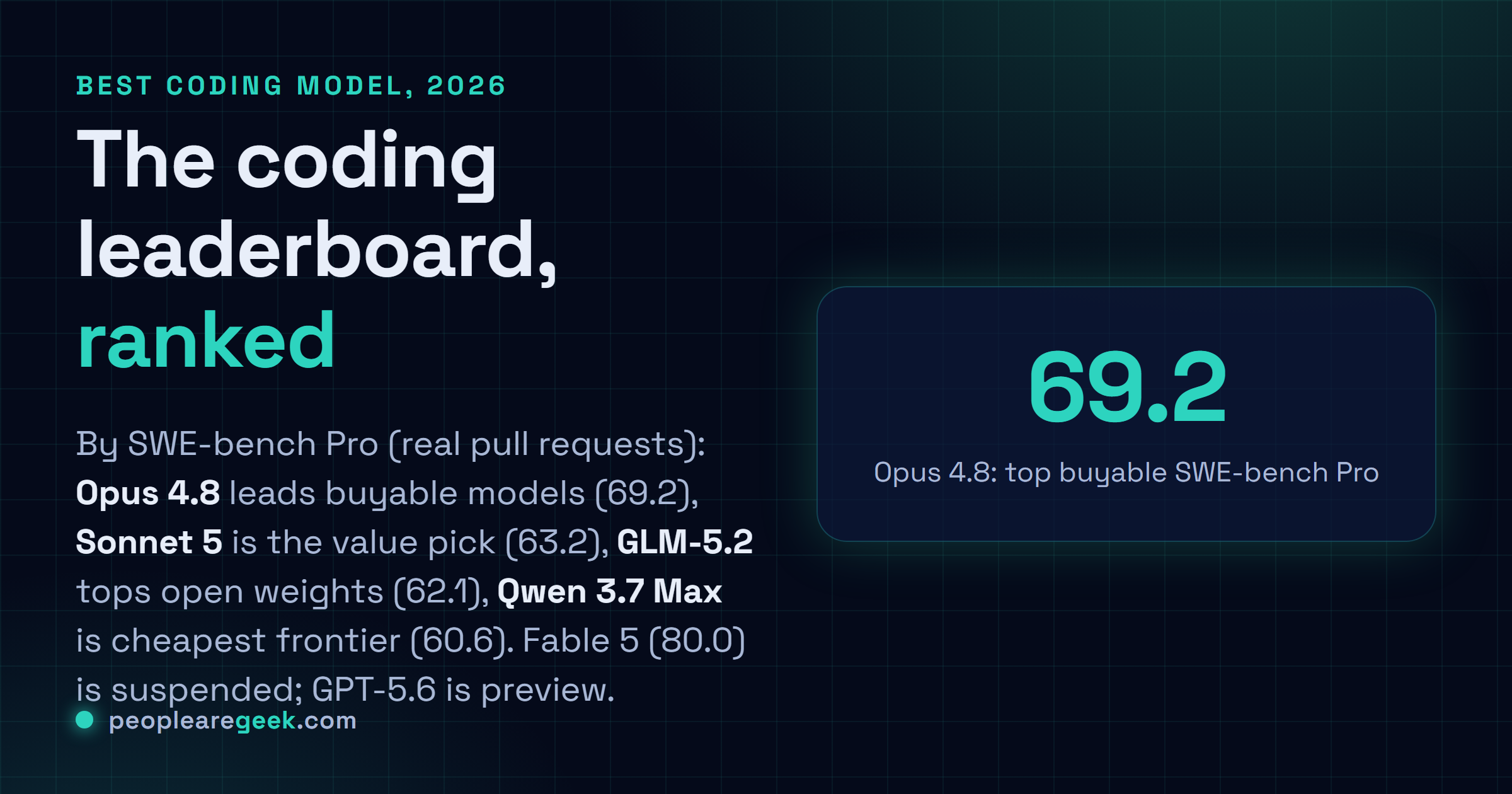
The best AI model for coding in 2026 is not a single name, it is a short list ranked by one honest number: SWE-bench Pro, the benchmark built from real repository pull requests rather than toy puzzles. On that scale, and among the models you can actually buy, Claude Opus 4.8 leads at 69.2, Claude Sonnet 5 is the value pick just behind it, and the best open-weights models are closing fast. There are two asterisks worth stating up front: Claude Fable 5 holds the all-time record but is suspended, and GPT-5.6 tops some tests but is still a limited preview, so neither is a practical pick today. Here is the ranking, what each one is best at, and how to choose, with a link to the deep dive on every pick.
The short answer
Ranked by SWE-bench Pro, the real-pull-request benchmark: Claude Opus 4.8 (69.2) leads the models you can buy, Claude Sonnet 5 (63.2) is the value pick just behind, GLM-5.2 (62.1) tops open weights, and Qwen 3.7 Max (60.6) is the cheapest frontier API. Claude Fable 5 (80.0) holds the record but is suspended; GPT-5.6 leads some tests but is still a preview.
{kind=link}
Every month brings a new "best coding model" headline, so let us anchor this to something real: SWE-bench Pro, the benchmark built from actual repository pull requests, which correlates far better with day-to-day coding than the puzzle-style tests. We rank by that, we note the price, and we only put models you can actually use in the main table. Two of the highest scores in the world do not qualify on that last rule, and we will get to them. First, the ranking.
The ranking
Ranked by SWE-bench Pro, models you can buy and run today.
| # | Model | SWE-bench Pro | Price, per 1M | Best for |
|---|---|---|---|---|
| 1 | Claude Opus 4.8 | 69.2 | $5 / $25 | The deepest coding and hardest reasoning |
| 2 | Claude Sonnet 5 | 63.2 | $3 / $15 (intro $2/$10) | Best all-round value |
| 3 | GLM-5.2 (open) | 62.1 | open weights | Best model you can self-host |
| 4 | Qwen 3.7 Max | 60.6 | $2.50 / $7.50 | Cheapest frontier-class API |
| 5 | MiniMax M3 (open) | 59.0 | open weights | Open alternative to GLM |
| 6 | GPT-5.5 | 58.6 | $5 / $30 | The OpenAI incumbent |
Two asterisks sit above this table. Claude Fable 5 scored 80.0, the all-time high, but it is suspended and unavailable. GPT-5.6 leads tests like Terminal-Bench in its preview, and its Sol tier will likely challenge the top, but it is a limited preview for about 20 organizations, not something most teams can deploy.
Best overall you can buy: Claude Opus 4.8
At 69.2 on SWE-bench Pro and 88.6 on the easier SWE-bench Verified, Opus 4.8 is the strongest coding model you can actually put a credit card behind. It is Anthropic's most autonomous model for long-horizon agentic work, and it is where the last few points of accuracy on genuinely hard, multi-step changes come from. The cost is the flagship price, 5 dollars input and 25 output per million. Whether it is worth that over Sonnet 5 depends entirely on your workload, which is exactly the question we answer in Claude Sonnet 5 vs Opus 4.8.
Best value: Claude Sonnet 5
Sonnet 5 is the story of 2026's coding models. At 63.2 it sits just behind Opus, it actually beats Opus on terminal-driven agent tasks, and it costs 40 percent less at standard pricing (60 percent during the introductory period). For the large majority of coding work, it is the sensible default, and it is generally available today, including in Claude Code. If you are also weighing it against OpenAI, see Claude Sonnet 5 vs GPT-5.6.
Best open weights: GLM-5.2 and the local route
If you want a model you can download and run yourself, GLM-5.2 leads the open field at 62.1, with MiniMax M3 close behind at 59.0. Both land within a few points of the top closed models, which was not true a year ago. For privacy, offline use, or unlimited generation without a per-token meter, open weights are now a serious choice, not a compromise. To actually set one up on your own hardware, our guide on running Qwen locally covers the Ollama path, hardware tiers, and quantization, and the same steps apply to GLM and MiniMax.
Cheapest frontier API: Qwen 3.7 Max
Among closed, frontier-class models, Qwen 3.7 Max is the value leader at 60.6, and it undercuts everyone on price at about 2.50 input and 7.50 output per million, roughly a third of GPT-5.5's output cost. It genuinely wins real-world coding for the money, which is why it earns its own deep dive against OpenAI in Qwen 3.7 Max vs GPT-5.5. On raw cost per solved task, Claude Haiku 4.5 is even cheaper, at roughly 13 cents of output per benchmark point, ideal for high-volume, simpler coding tasks.
The asterisks: suspended and preview
Two models score higher than anything in the table but do not count as practical picks. Claude Fable 5 holds the record at 80.0, but it and Mythos 5 have been suspended, so you cannot use them, a story we covered in the Fable 5 and Mythos 5 suspension. GPT-5.6 leads several tests in preview, and its tiers are worth understanding before it opens up, which we break down in GPT-5.6 Sol vs Terra vs Luna. Both are signs that the ceiling is higher than the current for-sale leaderboard shows.
How to pick, and try it
Strip it back to the decision. For most teams: default to Sonnet 5, escalate the hardest jobs to Opus 4.8, and reach for open weights (GLM-5.2 or a local Qwen) when privacy or cost demands it. Qwen 3.7 Max is the cheapest frontier API, and Haiku 4.5 is the cost-per-task champion for simple work. The good news is that trying the top picks takes minutes.

{kind=link}
The bottom line
The best AI model for coding in 2026, among the ones you can buy, is Claude Opus 4.8, but the more useful answer is that Claude Sonnet 5 made "just use the flagship" the wrong default for most teams, open weights got good enough to matter, and the true frontier (Fable 5, GPT-5.6) is sitting just out of reach. Match the model to the job, keep an eye on the preview tier, and re-check the ranking often, because at this pace it will move again next month.
Sources and further reading
- SWE-bench Pro leaderboard (morphllm)
- Best AI model for coding, ranked by SWE-bench Pro and cost (morphllm)
- Claude benchmarks, every model and price (morphllm)
- SWE-bench Pro leaderboard 2026 (CodingFleet)
Frequently asked questions
What is the best AI model for coding in 2026?
Of the models you can actually buy, Claude Opus 4.8 leads, scoring 69.2 on SWE-bench Pro (the real-pull-request benchmark) and 88.6 on the easier SWE-bench Verified. But Claude Sonnet 5 at 63.2 is the value pick, near the top for 40 to 60 percent less money. Claude Fable 5 holds the all-time record at 80.0 but is suspended and unavailable, and GPT-5.6 is still a limited preview, so neither counts as a practical choice yet. For most teams the honest answer is Sonnet 5 by default, Opus 4.8 for the hardest work.
What is the best open-source model for coding?
GLM-5.2 leads the open-weights field on SWE-bench Pro at 62.1, ahead of MiniMax M3 at 59.0. Both are within a few points of the top closed models, which is remarkable for weights you can download and run yourself. If your reason for going open is privacy or self-hosting, that is now a genuinely strong option. To run an open model on your own hardware, our guide on running Qwen locally walks through the practical setup with Ollama.
What is the cheapest good coding model?
By cost per solved task, Claude Haiku 4.5 is the cheapest, at roughly 13 cents of output per benchmark point, solving a large share of tasks at a fraction of the flagship price. Among frontier-class API models, Qwen 3.7 Max is the cheapest at about 2.50 dollars input and 7.50 output per million, roughly a third of GPT-5.5's output price. Claude Sonnet 5's introductory rate of 2 and 10 also makes it very cost-effective for its score.
Why is GPT-5.6 not at the top of the ranking?
Because most people cannot use it yet. GPT-5.6, and its flagship Sol tier, is a limited preview for about 20 partner organizations, not in ChatGPT, with general availability promised in the coming weeks. On some tests, like Terminal-Bench, it leads the field, so it will likely challenge the top once it opens up. We rank models teams can actually deploy today, which is why it sits in the honorable-mention section rather than the main table.
Is Claude Fable 5 really the number one coding model?
On the all-time SWE-bench Pro chart, yes, at 80.0, well ahead of everything else. The catch is that Claude Fable 5, along with Mythos 5, has been suspended, so you cannot use it. That is why our ranking of practical picks is led by Claude Opus 4.8 at 69.2, the best score among models you can actually buy and run. Fable 5 is the reminder that the frontier is higher than what is currently for sale.